
- Автор темы
- #1
Составил регулярное выражение для текста (изображен на картинке), но ничего не возвращает. Цель получить содержимое тега a. Подскажите, что не так написал.
PHP:
preg_match_all('/<div\s+class=[\'"]main[\'"]>+\n+\t{6}+\n+\t{7}+<a\s+href=[\'"](.*)[\'"]>/', $html, $result);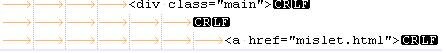
")